Protocol Buffers, commonly known as Protobuf, are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data. It’s similar to XML and JSON but is more efficient and quicker over the network. Protobuf is crucial for applications where high performance and minimal storage are required, particularly in service-oriented architectures like gRPC API.
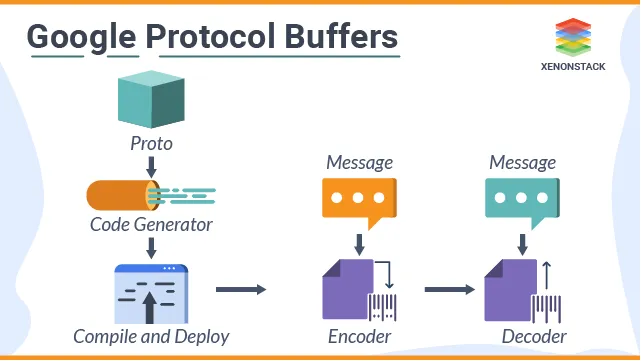
How It Works
Protobuf involves several key steps in data handling:
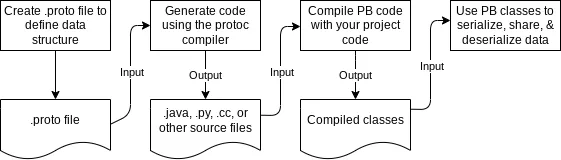
Define Data Structure: You describe your data using a special language-neutral, platform-neutral .proto file. This definition includes specifying simple data types such as integers, booleans, floats, or complex types like enumerations and messages.
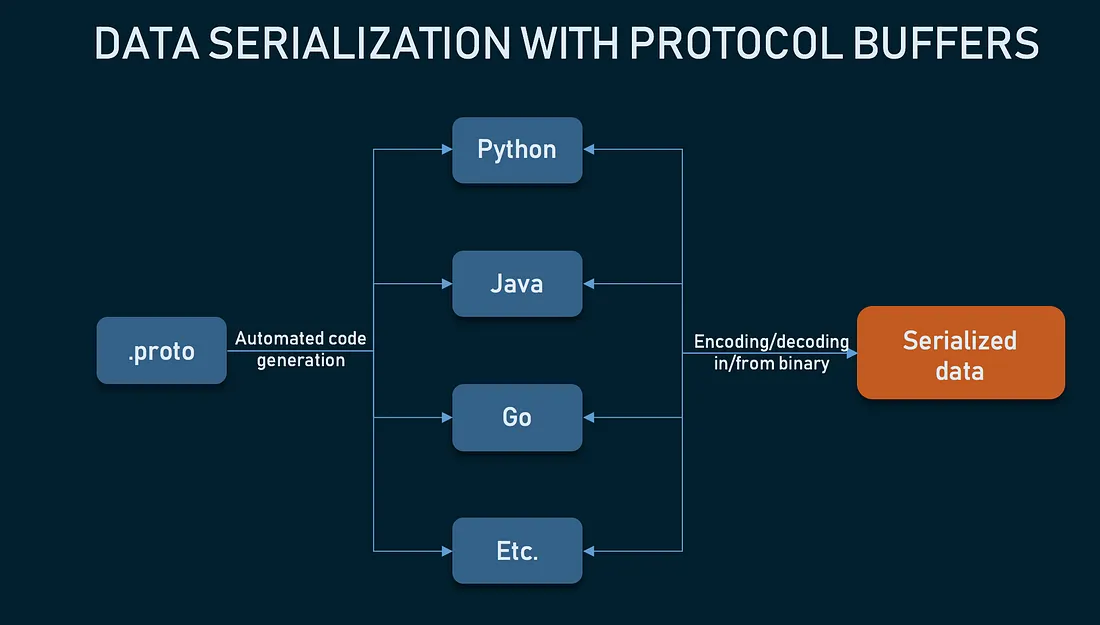
Compile with protoc: The .proto file is compiled by the protoc compiler, which generates source code in the developer’s chosen programming language. This auto-generated code provides APIs for manipulating the protobuf data types in a natural manner for each language.
Serialization/Deserialization: Data structured according to the .proto file is serialized into a compact binary format when it is sent over a network or saved to disk. The recipient can deserialize this binary data back into a usable form using the same .proto file.
Important
Efficient Data Encoding: Compared to JSON, which uses text, Protobuf’s binary format significantly reduces payload size, enhancing both transmission speed and efficiency.
Note
Data Format Flexibility: Protobuf supports advanced data schemas including optional, required, and repeated fields, allowing for complex data structures suitable for various application needs.
Protocol Buffers (Protobuf) provide a flexible, efficient, and automated mechanism for serializing structured data. They are used extensively in communications protocols and data storage solutions.
Basic Components
Data Types
Protobuf supports several primitive data types and allows for custom defined structures:
Basic Types: Includes int, float, double, boolean, and string.
Enums: Defines a set of possible values for a field.
Messages: Custom complex types that are made up of multiple fields and can be nested.
Field Rules
Fields in a Protobuf message can be categorized based on their required presence:
optional: Fields can be omitted. All fields in proto3 are optional by default.
repeated: Indicates an array of values. There is no limit on the number of values.
oneof: Allows only one of the fields within a set to be set at any time.
Unique Identifiers
Each field in a Protobuf message definition must be tagged with a unique number. These numbers are crucial as they are used in the message’s binary format:
message Student { string id = 1; string name = 2;}
Syntax Example
Here’s how you define a simple message in a .proto file:
syntax = "proto3";package demo;message Student { string id = 1; string name = 2;}
Serialization
Data structured by Protocol Buffers is serialized into a compact binary format. For instance, a student record like { "id": "S101", "name": "test" } would be serialized into a byte stream that may look abstracted as 124S101224test. This includes:
Field numbers and type information.
Data length and actual data.
Important
In the above message, 1 is Field Identifier, 2 is for data type- which is string, 4 is for the length of the data and next is the field value (4 characters)
Again for field 2, the type is 2 (String) and 4 characters (test)
We can clearly see that JSON is highly readable but the Protobuf takes less space when compared to JSON
Protocol Buffers offer a robust and efficient solution for serializing structured data, especially in environments where performance and resource utilization are critical. By optimizing both the size and speed of data exchange, Protobuf supports the development of scalable and fast applications.