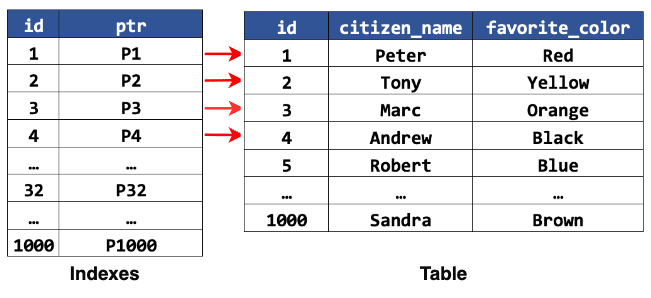
Indexing is a crucial feature in database management that enhances the performance of data retrieval operations by creating quick access paths to the data stored in a database. By effectively using indexes, databases can significantly reduce the amount of data they need to sift through when performing queries, leading to faster search times and improved application performance.
Important
Indexing acts much like a book’s index, enabling the database to find data quickly and efficiently instead of reading through all the table rows sequentially.
Why is Indexing Important?
Indexes are essential for enhancing the performance of database queries, particularly for large datasets. They are crucial for:
Speeding up data retrieval: Indexes provide fast data access, reducing response times.
Minimizing server load: By improving query performance, indexes reduce the load on a database server, which can otherwise be significant for data-intensive operations.
Improving efficiency of query processing: Indexes help in executing queries more efficiently by avoiding full table scans.
Types of Indexes
Clustered Indexes
A clustered index determines the physical order of data in a table. It sorts and stores the data rows in the table based on the indexed key. There can be only one clustered index per table, as the data rows themselves are sorted and stored in that order.
Physical Order Storage: The data is stored on disk in the same order as the indexed columns.
Efficiency in Range Queries: Ideal for range searches as it allows sequential disk reads.
Example SQL Command:
CREATE CLUSTERED INDEX idx_OrderDate ON Orders (OrderDate);
Non-Clustered Indexes
Unlike clustered indexes, non-clustered indexes maintain a separate structure from the data at the table rows. These indexes contain pointers to the physical rows for each entry. A table can have multiple non-clustered indexes.
Separate Structure: Maintains a different structure which includes pointers to the table’s rows.
Flexible and Numerous: A table can have multiple non-clustered indexes, making them versatile for various query types.
Differences between Clustered and Non-Clustered Indexes
The primary distinction between these two types of indexes lies in their storage format and the impact on performance:
Unique Clustered Index: As there can be only one clustered index per table, it defines the physical order of the data.
Multiple Non-Clustered Indexes: Multiple non-clustered indexes can exist, providing greater flexibility but potentially using more disk space due to additional structures.
Performance: Clustered indexes generally offer faster access for queries that benefit from the physical ordering of the data, such as range queries. Non-clustered indexes are beneficial for quick lookups based on the index keys.
Disk Space Usage: Non-clustered indexes may require more disk space as they store additional structures separate from the table data.
Maintenance: Clustered indexes can affect the physical ordering of the table, which might require more time to create or modify. Non-clustered indexes, being separate from the data, can be added or removed with less impact on the existing data layout.
Note
There are a lot of other indexing types. If you are interested and want to dive deeper check the References for more info