link: Non-Relational Databases
Graph Databases
Content
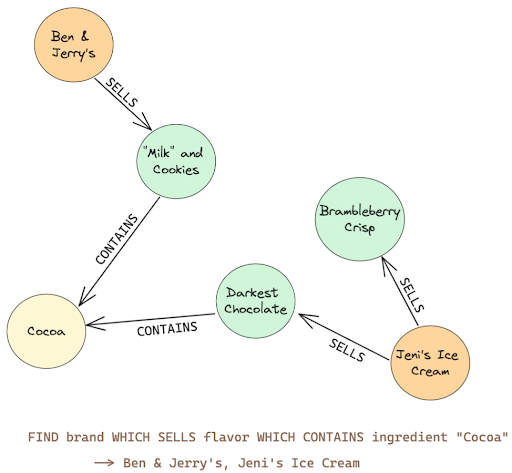
Graph databases use a structure that allows them to excel in managing complex relationships between data points. They store data in nodes and edges, where nodes represent entities and edges represent the relationships between them. This format is particularly suited for analyzing interconnected data and navigating relationships in a flexible and efficient manner.
Important
- Nodes: Represent entities such as people, businesses, accounts, or any item that can be represented as a data point.
- Edges: Define the relationships between nodes. They can include directions, labels, and properties that provide more context about the relationships.
- Schema-less: Graph databases typically do not require a predefined schema, allowing them to adapt to changes in data structures without costly database redesigns.
- Traversal Performance: These databases are optimized for traversing complex relationships and can quickly navigate through large networks of connections.
Example
- Neo4j: One of the most popular graph databases, known for its powerful querying capabilities and ease of use for developers.
- ArangoDB: A multi-model database that supports graph, document, and key-value data models in one core and API.
- JanusGraph: An open-source, scalable graph database optimized for storing and querying large graphs distributed across a multi-machine cluster.
- OrientDB: A versatile database supporting complex relationships with deep traversal capabilities, suitable for managing complex, interconnected data.
Graph databases are ideal for applications such as social networking, recommendation engines, fraud detection, and any scenario where relationships between data points are crucial. They provide high-performance querying, even for deep relationships, making them a preferred choice for complex data landscapes.