link: Cloud Architecture, Distributed Systems, Database
Data Replication

Overview
Data replication is the process of copying and maintaining database objects, such as data, schema, and transactions, in multiple locations to ensure consistency, availability, and reliability of data across distributed systems. This technique is critical for achieving high availability, disaster recovery, load balancing, and improved read performance in cloud and distributed computing environments.
Key Concepts
Data replication involves several key principles to ensure that data remains consistent and available across multiple locations:
Summary
Synchronous Replication: Ensures that data is simultaneously updated across all replicas. While it guarantees consistency, it may introduce latency.
Asynchronous Replication: Updates data across replicas with some delay. It is faster but may lead to temporary inconsistencies.
Full Replication: Copies the entire dataset to all replicas, ensuring high availability and fault tolerance but may consume more resources.
Partial Replication: Copies only a subset of the data to replicas based on specific criteria, optimizing resource usage and performance.
Multi-Master Replication: Allows multiple replicas to accept write operations, increasing availability and reliability but requiring conflict resolution mechanisms.
Master-Slave Replication: Designates one replica as the master for write operations, while other replicas (slaves) handle read operations, ensuring consistency and load balancing.
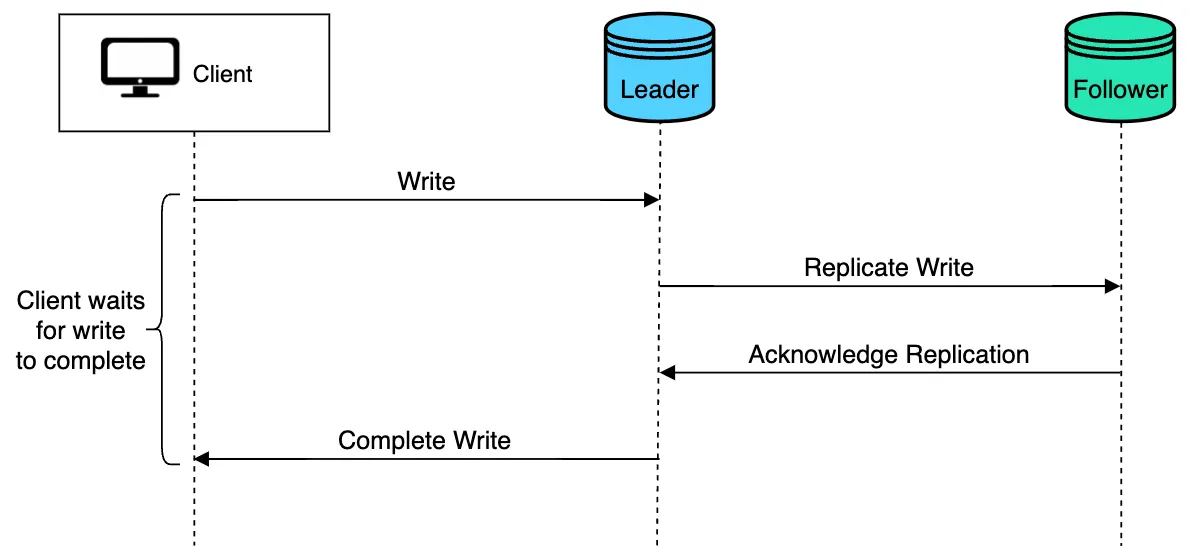
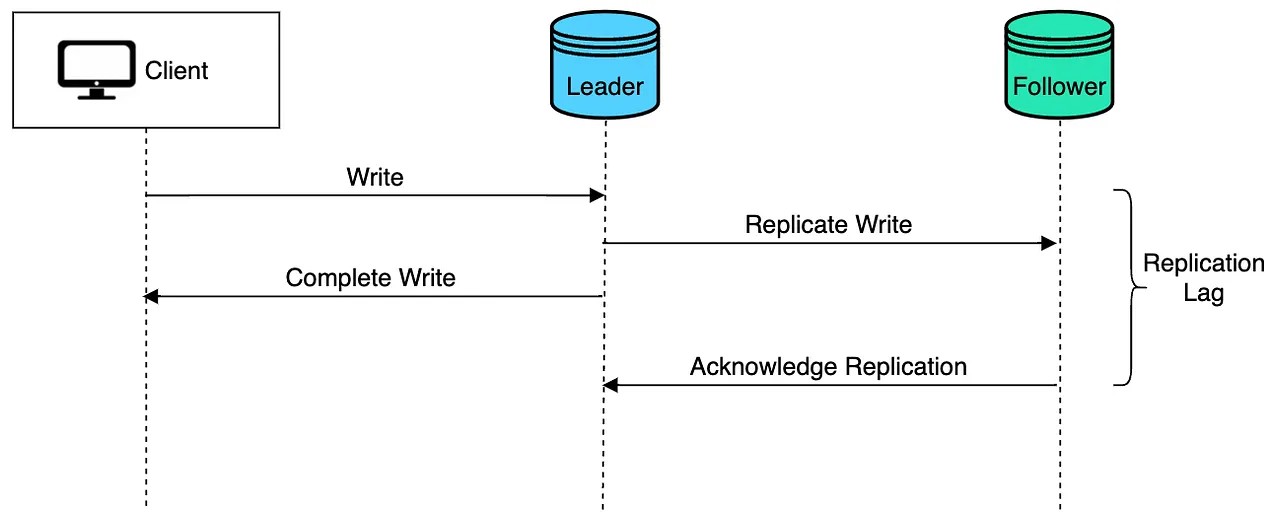
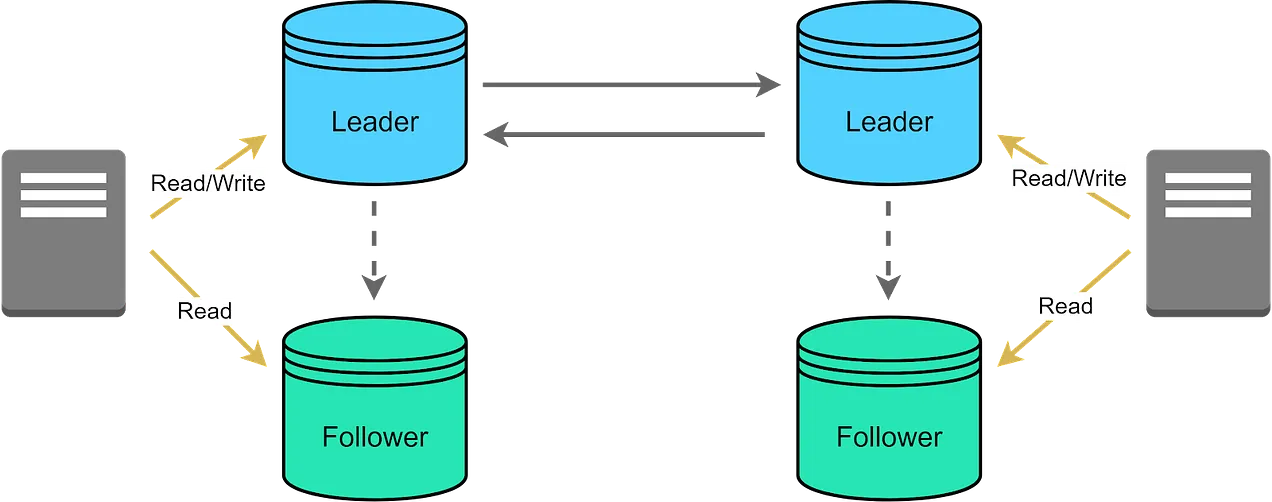
Pros and Cons
Data replication offers several advantages, particularly in cloud and distributed environments, but also comes with certain challenges that need to be addressed:
Pros
- High Availability: Ensures that data is always accessible, even in the event of hardware or network failures.
- Disaster Recovery: Provides backup copies of data that can be used to recover from catastrophic failures or data loss.
- Load Balancing: Distributes read and write operations across multiple replicas, enhancing performance and reducing bottlenecks.
- Improved Read Performance: Enables read operations to be distributed across replicas, reducing latency and improving response times.
Cons
- Consistency Management: Ensuring that all replicas have the same data, especially in asynchronous replication, can be complex.
- Conflict Resolution: Handling conflicts in multi-master replication scenarios requires robust conflict resolution strategies.
- Resource Overhead: Replication can consume significant network and storage resources, particularly in full replication setups.
Related Topics
Related Topics
- Distributed Systems: Data replication is fundamental in distributed systems to ensure data consistency and availability across different nodes, facilitating coordination and reliability in complex environments.
- High Availability: Data replication enhances high availability by providing redundant copies of data, allowing systems to remain operational during failures or maintenance.
- Fault Tolerance: Supports fault tolerance by maintaining multiple data copies, enabling systems to recover from hardware or software failures without data loss.
- Scalability: Facilitates scalability by distributing data across multiple nodes, allowing systems to handle increased loads efficiently and improve performance.
- Cloud Architecture: Integral to cloud architectures, where data is replicated across multiple data centers and regions for reliability, performance, and compliance with data residency requirements.
Summary
Data replication is a critical technique for ensuring data consistency, availability, and reliability in distributed and cloud computing environments. By implementing effective replication strategies, organizations can achieve high availability, disaster recovery, and improved performance, while also addressing the challenges associated with maintaining data consistency and resolving conflicts.
References
How to Choose a Replication Strategy Data Replication: A Key Component for Building Large-Scale Distributed Systems